Webinar
Nearly 80 percent of research data currently collected is deemed not reusable, since datasets might be unstructured and do not contain rich metadata. Standardizing research data at the source with ontologies and domain-specific semantic data models allows one to make their collected data FAIR (Findable, Accessible, Interoperable, and Reusable) and machine-readable at the time of collection.
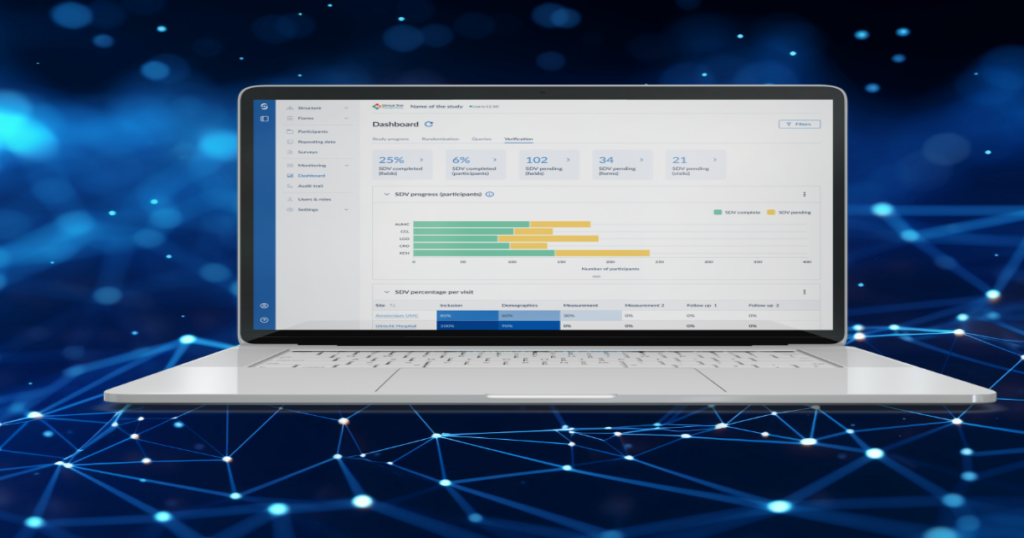
Discover all the features offered by Castor EDC
Discover Now