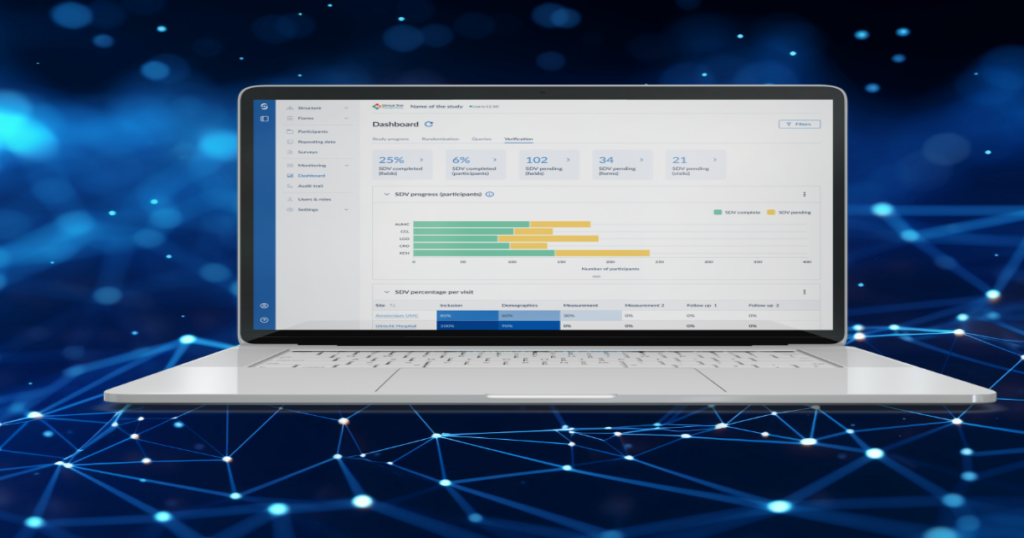
Success in life sciences research is all about transforming research findings into actionable knowledge. In this context, FAIR stands for Findable, Accessible, Interoperable and Reusable data, four critical elements to improve research infrastructure, making it easier for researchers to collaborate, ultimately improving the quality of healthcare in general.
#FAIRdata is a key topic at The Dutch Techcentre for Life Sciences (DTL)’s 2018 Conference, which we are proud to support. DTL provides a helpful description of each of the four elements on their website:
Findable – Data and metadata should be easy to locate, both by humans and by computer systems. Basic machine-readable descriptive metadata enable the discovery of interesting datasets and services.
Accessible – Stored for long term so that they can easily be accessed and/or downloaded with well-defined license and access conditions (open access when possible), whether at the level of metadata, or at the level of the actual data
Interoperable – Ready to be combined with other datasets by humans or computers
Reusable – Ready to be used for future research and to be further processed using computational methods
These FAIR principles are perfectly aligned with Castor’s goal of helping “accelerate medical research by unlocking the potential of every byte of research data.”
Click here if you would like to learn more about the FAIR data specification.
Concerns over data quality and usability
Over the years, as an MD and a researcher myself, I have become more and more concerned about the quality and the (re-)usability of data. In fact, approximately 85% of medical research data is never re-used due to poor data quality, lack of standardization, and by the data being inaccessible to others. I started Castor EDC in 2012 to address these issues and was happy to learn about the FAIR principles, which were published in 2016. This, in addition to other important initiatives such as the European Open Science Cloud (EOSC), are fostering global data findability and accessibility.
Open Science is an umbrella term for new technologies and a data driven systemic change in how researchers work, collaborate, share ideas, disseminate and reuse results. It is built on a foundation of core values that knowledge should be reusable, modifiable and redistributable.
The Commission “High Level Expert Group European Open Science Cloud” chaired by Barend Mons has published a first report on how the EOSC can be realized.
You can learn more about DTL’s vision regarding Open Science here.
Incorporating FAIR principles into Castor EDC
At Castor, one of our main goals for the next few years is to become a pioneering player in the field of Open Science. This means we will prioritize the development of data FAIRification within Castor EDC. By allowing researchers to expose their Castor data in a FAIR manner, research data can be shared easily between research projects worldwide.
At the 2016 BYOD hackathon in Leiden, Netherlands, Castor’s CTO, Sebastiaan Knijnenburg, PhD, and I spent three days learning about the FAIR specifications and trying to implement them into Castor. In just three short days we managed to extend our API and transform Castor into a FAIR data point.

We also managed to implement a Resource Description Framework (RDF) endpoint. We added semantic metadata to a Castor study and allowed the export of this study data in the RDF format. Two other software solution providers, OSSE (Open Source Registry System for Rare Diseases in the EU) and RDRF (Rare Disease Registry Framework) also worked on generating FAIR API endpoints for their software. (Learn more about medical device registry studies here.)
As a result, on the last day, data from a case study in all three systems could be queried and analyzed together, even though the original datasets were developed separately and did not share the similar structure.
Every dataset should be FAIR
In my view, every dataset in the world should become FAIR, not just those with funding to pay for FAIR data stewardship. This is why Castor is joining forces with several partners, such as DTL, that support Open Science to create an infrastructure that allows researchers to create semantic data models themselves. They can then actually create FAIR data at the source. Once we get this to work for all the studies in our system, FAIR will really start to shine. By enabling FAIR data at scale, researchers can easily make their clinical research data available for the FAIR research community. This way, both humans and computers will be able to search and filter through a dataset on a semantic level.
That said, semantic modeling is an area we can improve, as it is currently very labor intensive and can only be done with the help of experts. I have some ideas on making the creation of FAIR data accessible for everyone, and I will be working on these ideas in the coming years with FAIR scientists from across the globe.
Start small
As beautiful as fully interoperable, machine-readable data are, just the ability to find and access research data globally will make a big difference. Having the FAIR data points available, with a simple Comma Separated Value (CSV) download distribution for instance, will already be a big improvement in the short term.
The ultimate goal is user-created scalable content
We should work together towards enabling user-created scalable FAIR data. I think that would be the key to success. As soon as researchers start to realize the potential of FAIR –like the European Science Cloud– it will make a big difference in their attitude towards sharing data.
Furthermore, once people see the immense savings that a standardized data set can make, it could lead to initiatives that can contribute to making valuable medical data universally available.
Going forward
Showing the world how awesome user-created scalable FAIR data is and how useful it can be is a very important first step.
We at Castor have applied for grant funds to enable us to put more effort into working on scalable FAIR data and to demonstrate its overall benefits.